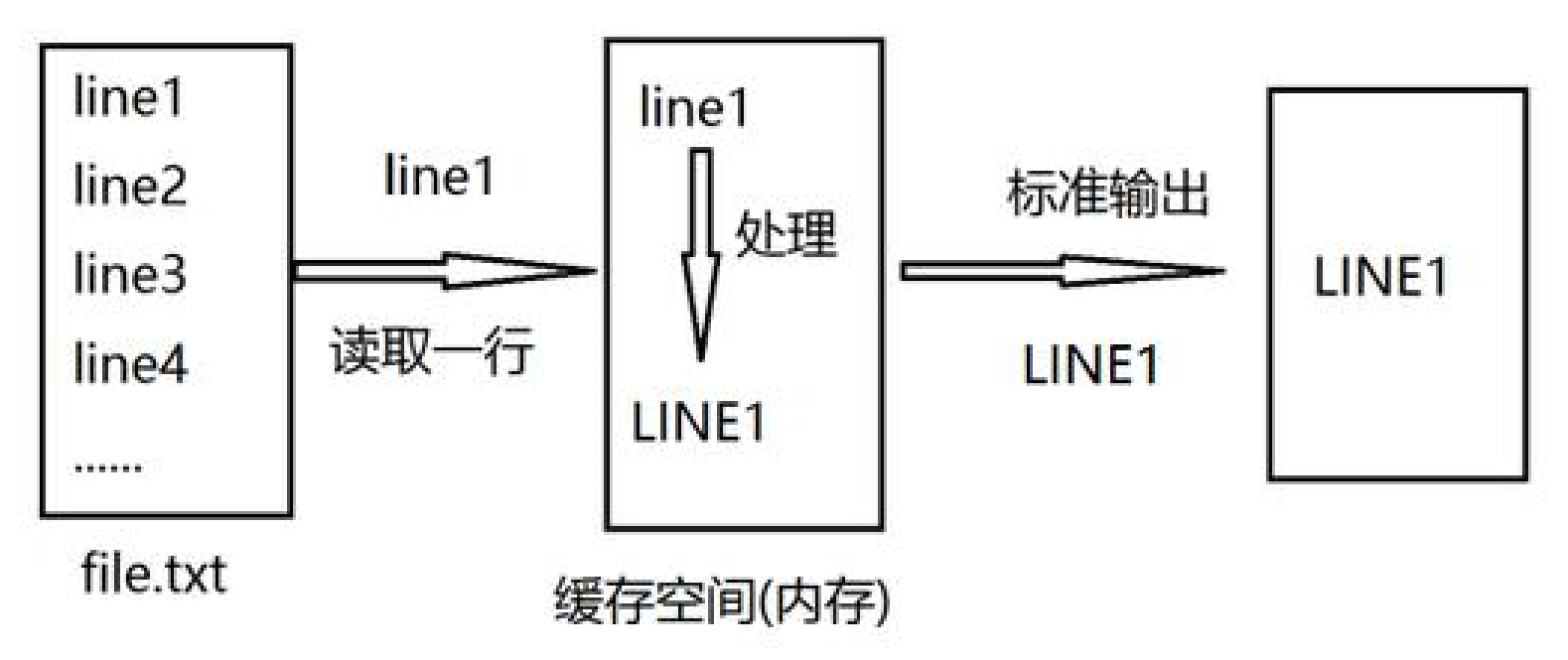
一、查看类工具
1.1 不分页查看文本
1.1.1 cat
[root@rocky8 ~]#cat --help
Usage: cat [OPTION]... [FILE]...
常用参数
-E:显示行结束符$
-A:显示所有控制符
-n:对显示出的每一行进行编号
-b:非空行编号
-s:压缩连续的空行成一行
示例:
[root@rocky8 ~]#cat -A test.txt
a^Ib c$
d $
e^If$
g k$1.1.2 nl
相当于cat -b filname 带行号显示文本
[root@rocky8 ~]#nl test.txt
1 a b c
2 d
3 e f
4 g k
[root@rocky8 ~]#cat -b test.txt
1 a b c
2 d
3 e f
4 g k1.1.3 tac
逆向显示文本内容
[root@rocky8 ~]#cat test2.txt
1
2
3
4
5
6
7
8
[root@rocky8 ~]#tac test2.txt
8
7
6
5
4
3
2
11.1.4 rev
逆向显示同一行的内容
[root@rocky8 ~]#cat test3.txt
1 2 3 4 5
a b c
[root@rocky8 ~]#tac test3.txt
a b c
1 2 3 4 5
[root@rocky8 ~]#rev test3.txt
5 4 3 2 1
c b a1.2 分页查看文本工具
1.2.1 more
[root@rocky8 ~]#more --help
Usage:
more [options] <file>...
-d: 显示翻页及退出提示
[root@rocky8 ~]#more /var/log/messages
Aug 5 11:39:02 rocky8_210 rsyslogd[973]: [origin software="rsyslogd" swVersion="8.2102.0-7.el8" x-pid="973"
x-info="https://www.rsyslog.com"] rsyslogd was HUPed
...1.2.2 less
less 也可以实现分页查看文件或STDIN输出,less 命令是man命令使用的分页器
[root@rocky8 ~]#tree -d /etc/|less
/etc/
├── alternatives
├── audit
│ ├── plugins.d
│ └── rules.d
├── authselect
│ └── custom
1.3 显示文本前后显示的内容
1.3.1 head
可以显示文件或标准输入的前面行
head [OPTION]... [FILE]...
-c 指定取第几行的内容
-n 指定获取前#行,#如果为负数,表示从文件头取到倒数第#前
[root@rocky8 ~]#cat test2.txt
1
2
3
4
5
6
7
8
[root@rocky8 ~]#head -2 test2.txt
1
2
[root@rocky8 ~]#head -n -2 test2.txt
1
2
3
4
5
61.3.2 tail
和head相反,为查看文本倒数第几行的内容
tail [OPTION]... [FILE]...
-c # 指定获取后#字节
-n # 指定获取后#行,如果#是负数,表示从第#行开始到文件结束
-# 同上
-f 跟踪显示文件fd新追加的内容,常用日志监控,相当于 --follow=descriptor,当文件删除再新
建同名文件,将无法继续跟踪文件
-F 跟踪文件名,相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文件
示例:
[root@rocky8 ~]#tail test2.txt
1
2
3
4
5
6
7
8
[root@rocky8 ~]#tail -3 test2.txt
6
7
8
实时查看日志文件
[root@rocky8 ~]#tail -f /var/log/messages
Aug 11 10:32:00 rocky8 dnf[1491]: AppStream 10 MB/s | 11 MB 00:01二、处理修改类
2.1 cut
cut 命令可以提取文本文件或STDIN数据的指定列
[root@rocky8 ~]#cut --help
Usage: cut OPTION... [FILE]...
-d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段,例如:3
#,#[,#]:离散的多个字段,例如:1,3,6
#-#:连续的多个字段, 例如:1-6
混合使用:1-3,7
-c 按字符切割
--output-delimiter=STRING指定输出分隔符
示例:以冒号为分割符显示第一行,三到四行,第七行的内容
[root@rocky8 ~]#cut -d: -f1,3-4,7 /etc/passwd
root:0:0:/bin/bash
bin:1:1:/sbin/nologin
daemon:2:2:/sbin/nologin
adm:3:4:/sbin/nologin
......
取出ip命令中的IP地址
[root@rocky8 ~]#ip a s eth0 | head -3 | tail -n1 |cut -d" " -f6|cut -d"/" -f1
10.0.0.210
提取分区利用率
[root@rocky8 ~]#df|tr -s ' ' |cut -d ' ' -f5 |tr -d %
Use
0
0
2
0
7
19
02.2 paste
按照行合并文件
-d #分隔符:指定分隔符,默认用TAB
[root@rocky8 ~]#cat test2.txt
1
2
3
4
5
6
7
8
[root@rocky8 ~]#cat test3.txt
1 2 3 4 5
a b c
[root@rocky8 ~]#paste test2.txt test3.txt
1 1 2 3 4 5
2 a b c
3
4
5
6
7
8
指定分割符合并文件
[root@rocky8 ~]#paste -d":" test2.txt test3.txt
1:1 2 3 4 5
2:a b c
3:
4:
5:
6:
7:
8:
多行合并一行
[root@rocky8 ~]#seq 10 > test4.txt
[root@rocky8 ~]#cat test4.txt
1
2
3
4
5
6
7
8
9
10
[root@rocky8 ~]#paste -s test4.txt
1 2 3 4 5 6 7 8 9 10三、分析类
3.1 wc
用于统计统计文件的行总数、单词总数、字节总数和字符总数
常用选项
-l 只计数行数
-w 只计数单词总数
-c 只计数字节总数
-m 只计数字符总数
-L 显示文件中最长行的长度3.2 uniq
命令从输入中删除前后相接的重复的行
常用选项
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
四、文件查找工具
4.1 find
实时查找工具,通过遍历指定路径完成文件查找
[root@rocky8 ~]#find --help
Usage: find [-H] [-L] [-P] [-Olevel] [-D help|tree|search|stat|rates|opt|exec] [path...] [expression]
4.1.1 常用查找条件
1.-name
根据文件名查找
2.-type
根据文件类型查找
f: 普通文件
d: 目录文件
l: 符号链接文件
s:套接字文件
b: 块设备文件
c: 字符设备文件
p: 管道文件
3.-user、-group、-uid、-gid
根据文件的属性查找
4.条件组合查找
与:-a ,默认多个条件是与关系,所以可以省略-a
或:-o
非:-not !4.1.2 处理动作
使用find查找文件之后还可继续执行打印、复制、删除等操作使用参数如下:
-print:默认的处理动作,显示至屏幕
-ls:类似于对查找到的文件执行"ls -dils"命令格式输出
-fls file:查找到的所有文件的长格式信息保存至指定文件中,相当于 -ls > file
-delete:删除查找到的文件,慎用!
-ok COMMAND {} \; 对查找到的每个文件执行由COMMAND指定的命令,对于每个文件执行命令之前,都会
交互式要求用户确认
-exec COMMAND {} \; 对查找到的每个文件执行由COMMAND指定的命令
{}: 用于引用查找到的文件名称自身4.2 locate
locate是另外一款文件查找工具,和find不同的是它不是实时查找,但是用法较为简单。在使用前先使用“updatedb”更新数据库
[root@rocky8 ~]#locate -h
Usage: locate [OPTION]... [PATTERN]...
Search for entries in a mlocate database.
-i 不区分大小写的搜索
-n N 只列举前N个匹配项目
-r 使用基本正则表达式示例
[root@rocky8 ~]#updatedb
[root@rocky8 ~]#locate fstab
/etc/fstab
/usr/lib/dracut/modules.d/95fstab-sys
/usr/lib/dracut/modules.d/95fstab-sys/module-setup.sh
/usr/lib/dracut/modules.d/95fstab-sys/mount-sys.sh
......五、文本处理三剑客
5.1 grep
grep命令用于抓取出文本的指定字符,可配合正则表达式一起使用。
基本用法
[root@rocky8 ~]#grep --help
Usage: grep [OPTION]... PATTERN [FILE]...
Search for PATTERN in each FILE.
Example: grep -i 'hello world' menu.h main.c
常用参数
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,即取反
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
-w 匹配整个单词
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-P 支持Perl格式的正则表达式
-f file 根据模式文件处理
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接基本正则表达式:
.:匹配任意单个字符(除了换行符)。
^:匹配行的开始。
$:匹配行的结束。
[]:匹配括号内的任意一个字符。
[^]:匹配不在括号内的任意一个字符。
():将表达式分组。
|:逻辑或操作符,匹配两个表达式中的任意一个。
*:匹配前面的字符零次或多次。
?:匹配前面的字符零次或一次。扩展正则表达式
\(...\):与基本正则表达式中的 () 类似,用于分组,但在 ERE 中需要使用反斜杠 \ 进行转义。
\|:逻辑或操作符,与基本正则表达式相同,但在 ERE 中需要转义。
+:匹配前面的字符一次或多次。
?:与基本正则表达式相同,匹配前面的字符零次或一次,但在 ERE 中需要转义。
{n}:匹配确定的 n 次。
{n,}:至少匹配 n 次。
{n,m}:最少匹配 n 次,最多匹配 m 次。
注:扩展正则需要和-E选项配合使用示例:提取分区占用率最高的数值
[root@rocky8 ~]#df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 459928 0 459928 0% /dev
tmpfs 479940 0 479940 0% /dev/shm
tmpfs 479940 6688 473252 2% /run
tmpfs 479940 0 479940 0% /sys/fs/cgroup
/dev/mapper/rl-root 38745616 2364960 36380656 7% /
/dev/nvme0n1p1 1038336 187332 851004 19% /boot
tmpfs 95988 0 95988 0% /run/user/0
[root@rocky8 ~]#df | grep '^/dev' |tr -s ' ' %|cut -d% -f5|sort -n|tail -1
19示例:哪个IP和当前主机连接数最多的前三位
[root@web1 ~]#ss -nt | grep "^ESTAB" |tr -s ' ' : |cut -d: -f6|sort |uniq -c|sort -nr|head -n3
3 120.230.139.127
1 100.125.158.120
范例: 连接状态的统计
[root@web1 ~]#ss -nta |grep -v '^State' | cut -d " " -f1 | sort |uniq -c
3 ESTAB
10 LISTEN
6 TIME-WAIT范例: 过滤掉文件的注释(包括#号的行)和空行
[root@rocky8 ~]#grep -Ev '^$|#' /etc/fstab
/dev/mapper/rl-root / xfs defaults 0 0
UUID=115aab42-785e-4ed7-ad05-430e3a030ba0 /boot xfs defaults 0 0
/dev/mapper/rl-swap none swap defaults 0 05.2 sed
sed即 Stream EDitor,和 vi 不同,sed是行编辑器,可用于对文本内容进行过滤、取行、替换、删除。
命令格式
sed [options] 'command' file(s)
sed [options] -f scriptfile file(s)常用选项
-n 不打印存储空间内容
-i 修改文件内容 -i.bak 备份文件并在原处编辑
-r -E 使用正则表达式
-r选项是与Perl兼容的正则表达式常用命令
1.替换操作;s命令
sed -i 's/找谁/替换成谁/g' filename
2.删除操作;d命令
删除空白行;sed '/^$/d' file
删除第二行;sed '2d' file
删除范围行,如第二行到最后一行;sed '2,$d' file
3.后向引用
表达形式:s###g
前面两个井号之间的数据通过正则配合()对数据进行分组
后面两个井号之间通过\数字去调用前面分组的内容。
总结来说就是后面调用前面的 内容称之为反向引用或者后向引用。
示例:输出1-8,通过sed把这串数字分组成1<234567>8
[root@rocky8 ~]#echo 12345678 | sed -r 's#(1)(.*)(8)#\1<\2>\3#g'
1<234567>8
4.在sed中使用变量
5.3 awk
awk可用于对文本数据进行过滤、取行、取列、统计计算、判断、循环等操作。
语法形式
awk [options] 'script' var=value file(s)
awk [options] -f scriptfile var=value file(s)awk的使用模式
1./正则表达式/ 使用通配符的扩展集
示例:
[root@rocky8 ~]#ss -antp|grep -i ESTAB|awk '$4~/:22$/'
ESTAB 0 52 10.0.0.210:22 10.0.0.1:14043 users:(("sshd",pid=1189,fd=5),("sshd",pid=944,fd=5))
2.关系表达式 使用运算符进行操作可以是字符串或者数字的比较测试
算术运算符:
x+y, x-y, x*y, x/y, x^y, x%y-x:转换为负数+x:将字符串转换为数值
赋值操作符:
=, +=, -=, *=, /=, %=, ^=,++, --
比较运算符:
==, !=, >, >=, <, <=
示例:
[root@rocky8 ~]#awk 'BEGIN{i=0;print i++,i}'
0 1
范例:取奇,偶数行
[root@rocky8 ~]#seq 10 | awk 'NR%2==0'
2
4
6
8
10
3.模式匹配表达式
用运算符~ (匹配)或 !~(不匹配)
~ 左边是否和右边匹配,包含关系
!~ 是否不匹配
4.BEGIN END PATTERN语句块
awk高级用法
1.加入变量使用
在awk中使用变量需要加上-v参数与shell环境中的变量区分开
示例:
[root@rocky8 ~]#name=sync
[root@rocky8 ~]#awk -F: -vn=$name '$1==n{print $NF}' /etc/passwd
/bin/sync
2.加入判断
if语句
示例:当使用率大于指定值则提示磁盘空间不足
[root@rocky8 ~]#df -h | awk '$NF=="/"{ if($5>=5) print "磁盘空间不足"}'
磁盘空间不足
[root@rocky8 ~]#df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 450M 0 450M 0% /dev
tmpfs 469M 0 469M 0% /dev/shm
tmpfs 469M 6.6M 463M 2% /run
tmpfs 469M 0 469M 0% /sys/fs/cgroup
/dev/mapper/rl-root 37G 2.3G 35G 7% /
/dev/nvme0n1p1 1014M 183M 832M 19% /boot
tmpfs 94M 0 94M 0% /run/user/0